Examining whether recruitment data can, and should, be used to train AI models for shortlisting interview candidates
Recruitment is a complex process where many factors need to be considered and understood so that the right candidates can be shortlisted for an interview. As well as that, it is a time-consuming process. However, the information provided in a job application has the potential to lead to bias if not handled correctly. This can happen with human shortlisters, but extra care must be taken if a machine (e.g. AI) is involved that is entirely unaware of what is and is not sensitive.
The challenge…
Can we identify where bias has potential to occur when using machine learning for shortlisting interview candidates as part of the NHS England recruitment process? How does this manifest, and how can it be mitigated?
Overview
Recruitment in the NHS involves identifying the best candidates for a wide array of jobs, where the skills typically vary significantly between roles. The process is very time consuming, with applications, CVs and other supporting documents reviewed to identify the best candidates. These candidates are then ‘shortlisted’ for an interview, which is the next step in the process. This shortlisting is done by often highly experienced hiring managers, who have a nuanced understanding of what makes a good candidate. However, the fact that humans are involved in this review process means decisions taken at this stage can vary, from person to person as well as between hiring rounds.
One way to gain some consistency might be to leverage artificial intelligence (AI), specifically machine learning, to undertake this process. The purpose of this project was to review the feasibility and consistency of this in the context of the NHS.
What do we mean by bias?
There are many ways to define bias depending on whether it is in relation to the data, design, outcomes or implementation of AI. In this piece of work, bias was investigated in the representativeness of the data set and the results of the predictive model using the distribution and balance of shortlisted candidates across groups of protected characteristics in those who applied.
When talking about bias by the predictive model, the model was determined to have shown ‘bias’ if the errors made in prediction were larger than an accepted error rate (which is defined by the person carrying out the work).
Bias can also be identified by looking at integrity of the source data (looking at factors such as the way it was collected) or sufficiency (see here) of the data
When machine learning is used for shortlisting, machines typically review the application and use a model to determine who to shortlist. In order to do this, a model is trained on historic shortlisting decisions to enable it to build an understanding of what makes a good candidate for an interview. However, the challenge with this approach is that any AI or machine learning model can only seek to replicate human decisions which are reflected historically in the data. If any human bias is present in the data that the model learns from, the model could replicate this bias, or worse, amplify it and make it an even more substantial problem than if humans were to continue the recruitment process. This occurs because a machine learning model looks for patterns in applications that led to shortlisting, and does not “understand” specific data points, or features, such as employment experience that meant the individual was well suited to being selected for an interview. This issue means it is vital that robust analysis and testing of models and their predictions are carried out to identify what bias, if any, has been replicated by the model.
The London Talent Team wanted to understand to what extent this was an issue - specifically how the data they held on hiring decisions might contain biases that could be taken on by any model that was trained using it.
What we did
To address this project, we worked for 4 weeks in 4 sprints with technology suppliers from the Accelerated Capability Environment (ACE), ultimately selecting a joint bid between Bays Consulting and Niaxo. Their bid was chosen as the approach aimed to clearly lay out whether or not bias was present in the data by applying explainable models with clearly laid out steps and carefully analysing the findings at each stage of the project. By using models which allow insight into how decisions were made, bias could more easily be identified if it were occurring.
Data held from each application was text-based and the chosen approach looked at the occurrance of specific words in each application, compared to all applications using a technique called “TF-IDF”. Using this information, a “logistic regression” model was built to predict whether or not a candidate was shortlisted.
A Logistic Regression model was then selected due to its simplicity, which meant that we could easily understand the mechanism used to make a decision (in comparison to a more black box model like a Neural Network).
Prior to training the model, the dataset was evaluated to identify whether any bias was present in the data which the model would learn from. Providing no bias was found in the dataset, that data could be used to train the model. Once training was complete, the model could be analysed to identify whether any bias was present in the model itself . After the model was trained and predictions were made, the predictions could be analysed to identify whether any bias had occurred in predictions. For example, Bays/Niaxo could identify features about applicants that performed better at predicting than we might expect, and those where the model fell short of expectations.
AI Dictionary
We have tried to explain the technical terms used in this case study. If you would like to explore the language of AI and data science, please visit our AI Dictionary.
Determining whether the dataset had any bias within it
The first stage of the project was to determine whether the dataset itself contained any bias. This was important because a dataset containing bias was likely to produce a model with bias too.
It was found that the dataset used contained proportionally fewer White people than the UK population average, and proportionally more people who were Black or Black British and Asian or Asian British. This was interesting to note, but did materially affect the approach to the project.
To understand whether there was any bias in the shortlisting process contained within the data, the shortlisting decisions were analysed across NHS job bands, broken down by sex and ethnicity. It should be noted that the vacancies examined as part of this project were NHS England & NHS Improvement roles, meaning that the majority were administrative-type jobs, rather than clinical roles. By looking at the counts and proportions of candidates shortlisted or not shortlisted, there was little variation in the shortlisting of subcategories within either sex or ethnicity, across all grades, identified (see Figure 1 below).
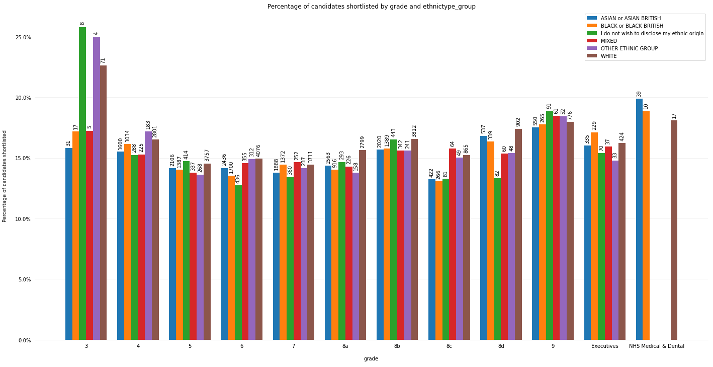
The dataset being free of bias in shortlisting across both sex and ethnicity meant that work could proceed to developing a model for shortlisting candidates. This would enable us to understand whether the modelling process causes bias in shortlisting.
Working out if the model exhibited bias in its predictions
With the dataset showing no clear signs of bias in shortlisting candidates, if a model trained using that dataset showed some element of bias then we can infer that the model has introduced that bias in decision making.
A Logistic Regression model was selected for prediction as it was simple and its decision making can be explained. The features produced using TF-IDF were fed into the model, and the model was trained to predict if a candidate would be shortlisted.
After training, the performance of the model could be evaluated. Bays/Niaxo looked to understand whether a model was biassed in its decision making by looking at the ‘miss rate’ of the model. That is how often a model predicted someone wouldn’t be shortlisted when in reality they were. This would indicate the model was more pessimistic than necessary about that candidate. By looking at miss rate across both sex and ethnicity, again broken up by NHS job bands, we would be able to identify characteristics where the miss rate is higher or lower than expected.
In order to evaluate miss rate, an acceptable miss rate of 20% was used. The model was tuned so that the overall miss rate was below 20%, and then predictions were evaluated across specific characteristics.
What was found was that the model is better at accurately shortlisting (e.g. miss rate is lower than 20%) women than men or candidates with no reported sex, as well as those over the age of 35 and those who are white. This is a potentially counter-intuitive finding, especially within ethnicity, where the proportion of candidates who are white is lower than the UK population average. Further work is needed to understand why the model has incorporated this bias.
Outcomes and lessons learned
The important finding here is that using machine learning models for shortlisting should be carefully thought through, with the potential impacts carefully understood before they are used in earnest. It should be emphasised that the findings of model performance here are strictly specific to this use case, and does not invalidate any work done by any other teams investigating or applying this type of approach.
The performance of the model here could be down to the split of the dataset, which is skewed towards women, who happen to be older, and while the proportion of white candidates is lower than the UK population average, they are still the most well represented ethnicity in the dataset. This combination could have caused the model to be better informed about what makes a good candidate for shortlisting in these characteristics, while having less data for the other ethnicities and sexes leading to reduced performance.
On the other hand, the model could genuinely be biassed against specific characteristics because of the way the variables for the model were generated (using TF-IDF). It could be that differences in language or writing style (to give just two examples) could be leading to a preference for some candidates over others. However this work did not explore this avenue, so would need to be addressed in any future package of work.
In either case, more work is needed to fully understand the outcomes that were seen within this project. There could be a much wider range of factors causing the discrepancy in performance, outside of the two mentioned above. This work acts as a jumping off point for exploring exactly how model bias manifests, if at all, in this type of problem.
What’s next?
The NHS AI Lab Skunkworks team is evaluating what the next best option would be in terms of extending this work, including future packages of work to understand the likely cause of the model performance issues.
Who was involved?
This project is a collaboration between NHS Transformation Directorate, NHS London Talent Team, Bays Consulting, Niaxo and the Home Office’s Accelerated Capability Environment (ACE). The AI Lab Skunkworks exists within the NHS AI Lab to support the health and care community to rapidly progress ideas from the conceptual stage to a proof of concept.
NHS AI Lab Skunkworks is a team of data scientists, engineers and project leaders who support the health and social care community to rapidly progress ideas from the conceptual stage to a proof of concept.
The NHS AI Lab is working with the Home Office programme: Accelerated Capability Environment (ACE) to develop some of its skunkworks projects, providing access to a large pool of talented and experienced suppliers who pitch their own vision for the project.
Accelerated Capability Environment (ACE) is part of the Homeland Security Group within the Home Office. It provides access to more than 250 organisations from across industry, academia and the third sector who collaborate to bring the right blend of capabilities to a given challenge. Most of these are small and medium-sized enterprises (SMEs) offering cutting-edge specialist expertise.
ACE is designed to bring innovation at pace, accelerating the process from defining a problem to developing a solution and delivering practical impact to just 10 to 12 week.
Further information
Access the project report here
Find out more about other projects at the NHS AI Lab Skunkworks.
Join our NHS AI Virtual Hub to hear about opportunities to get your AI project taken up by the Skunkworks team
Get in touch with the Skunkworks team at aiskunkworks@nhsx.nhs.uk.


